Inteligencia Artificial

Actualmente, los beneficios de implementar servicios de Inteligencia Artificial están al alcance de cualquier empresa, no sólo de las que destinan un gran presupuesto a la investigación como Tesla con sus automóviles de piloto autónomo. La convergencia de los servicios en la nube con su reducción de cosos en infraestructura, más la intensa actividad de la comunidad para alcanzar a la industria de software en poco tiempo los resultados de investigación y la apertura de proyectos de las grandes corporaciones (Google con TensorFlow, Facebook con PyTorch, Nvidia con CUDA, etc.) están montando una revolución tecnológica muy explosiva, en el sentido de que prácticamente no hay un campo en el que no se haya implementado un algoritmo de aprendizaje automático.
Ya sea para mejorar predicciones del clima, de desastres, financieros, fallas estructurales, recomendaciones sobre preferencias, reconocimiento biométrico, pilotaje autónomo, diagnóstico médico, controles de calidad, detección de fraudes y anomalías, chatbots, traductores, análisis de sentimientos en texto, reconocimiento de voz, videojuegos con dificultad adaptable, aplicaciones de reclutamiento de recursos humanos, entre muchos otros que ya son ejemplos clásicos, hasta la transferencia de arte para crear nuevas obras (una actividad que hasta hace poco tiempo considerábamos como exclusiva de los humanos) son sólo la punta del iceberg del potencial que apenas estamos explotando de la IA.
En Lychee Creatividad e Innovación nos encontramos en la capacidad de implementar proyectos de Aprendizaje Automático para alcance empresarial. Muchas de las tareas repetitivas hechas por personas pueden suplirse por sistemas de Aprendizaje Automático con menores costos.
Nuestro flujo de trabajo a grandes rasgos se muestra en la siguiente imagen:
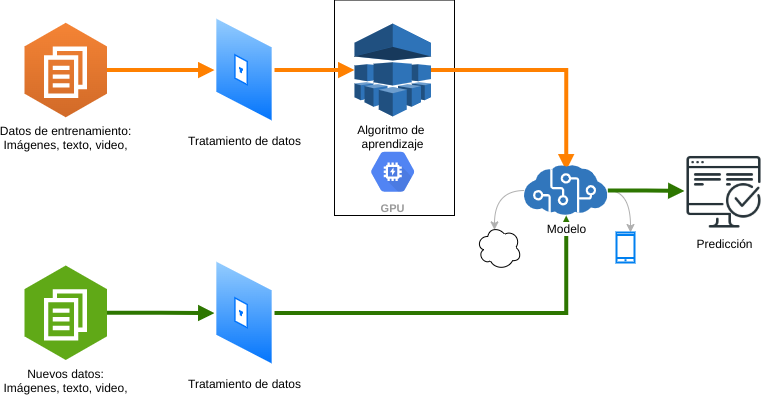
Veamos primero la ruta de color naranja:
Para un aprendizaje supervisado se requiere de un gran conjunto de datos etiquetados, esto es, datos digitales de interés de nuestro proyecto recolectados y con algún significado para las personas. Por ejemplo, en un sistema de control de calidad visual, pueden haber miles de fotografías con muestras de productos aceptables y muestras de productos rechazados por grietas, mal acabado, color no homogéneo, malformado, etc. Es probable que personas se encarguen de ese etiquetado de datos, aunque hay herramientas para que, a partir de un grupo de datos, se generen más de forma sintética.
Después, estos datos usualmente son pre-procesados para que las computadoras y los algoritmos de aprendizaje los trabajen de forma óptima. En ocasiones los modelos de aprendizaje trabajan con algún formato de datos o dimensiones preestablecido para que el entrenamiento con los datos recolectados y sus etiquetas sea óptimo. Es posible que en lugar de tener días trabajando a Unidades Gráficas de Procesamiento (GPU), se reduzca a horas y esto tiene también un impacto significativo en el costo del proyecto.
El entrenamiento del sistema mediante algún algoritmo de aprendizaje es la parte medular. El objetivo del entrenamiento es generar un conjunto de parámetros que modelará el sistema a partir de los datos de entrenamiento con la referencia de las etiquetas para que dicho sistema pueda predecir qué etiqueta le corresponde a nuevos datos. La idea es que una computadora emule en cierto sentido cómo las personas aprendemos, por ejemplo, que los objetos tienen cierta forma, color, y que se llaman de tal forma. Nuestro aprendizaje es iterativo y evolutivo, necesitamos en ocasiones de varias experiencias y al principio, de equivocarnos para aprender correctamente. Con las computadoras es similar, se necesitan de muchos datos para generar esas iteraciones de experiencias para que puedan llegar a clasificar o predecir cada vez mejor los resultados.
Actualmente existen tan solo para una tarea varios algoritmos de aprendizaje. La relación entre la investigación y la industria en Aprendizaje Automático es muy estrecha y está potenciada por las grandes compañías de software para tener disponibles algoritmos más potentes para una gran cantidad de dominios del conocimiento. Muchos de estos algoritmos son públicos y en relativamente corto tiempo están disponibles en marcos de desarrollo con lo que se tienen cada vez productos más sofisticados. Para un solo proyecto de Aprendizaje Automático se pueden probar varios algoritmos acorde a su dominio y comparar cuál tiene el mejor desempeño con un conjunto de datos de prueba.
Una vez que se cuentan con los parámetros del modelo con el mejor rendimiento, se despliega ya sea en la nube para hacer clasificaciones o predicciones en línea, o bien, en dispositivos móviles o en un sitio web para realizar las clasificaciones/predicciones en sitio.
En la ruta verde del diagrama, el modelo puede ser consumido por una o varias aplicaciones que deberán tratar los datos de forma similar a la ruta naranja, e ingresar los datos pre-procesados a dicho modelo para la predicción o clasificación en tiempo real o por lotes.